From The Sunday Times, 10th August 1975 [link]
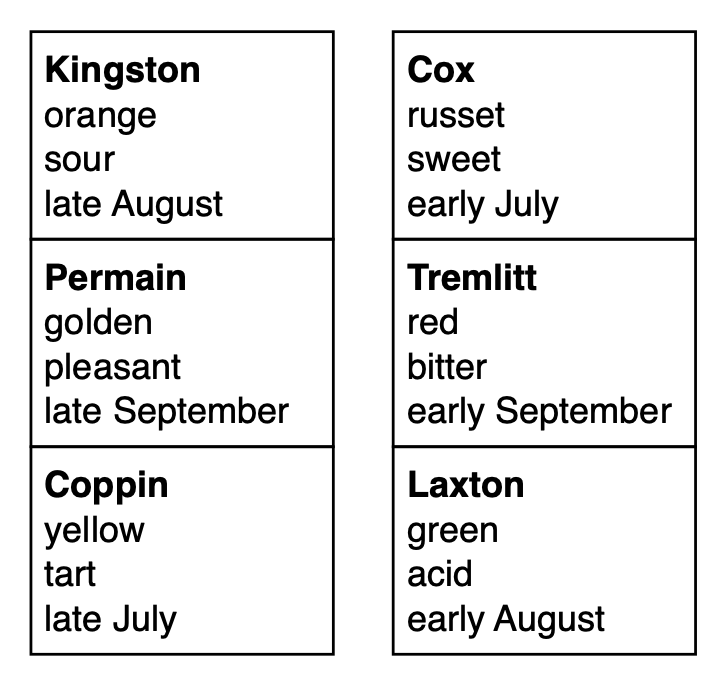
A farmer grows apples in an orchard divided into plots —three to the East and three to the West of a central path. The apples are of two types — for eating (Cox, Laxton, Pearmain) and for cider making (Tremlitt, Coppin, Kingston).
Adjacent plots contain apples of different basic type. The apples are of six colours (red, green, russet, golden, orange, yellow) and of six tastes (sweet, sour, acid, tart, pleasant, bitter).
They ripen at different times, either early or late in July, August and September. Those ripening in early or late September are in plots directly opposite. Those South of Pearmain do not ripen in August. Tart are directly West of the acid variety, which ripens in early August. Yellow apples and those maturing in late September are adjacent. Yellow and orange are of the same type. Orange are North of pleasant and also North of Pearmain. Kingstons are adjacent to golden. Green is South of bitter.
Cox ripen in early July, and Laxtons ripen early in a different month. Tremlitts are red, and Kingstons mature after Coppins, which are not sour.
If cider apples taste unpleasant, what are the characteristics of the apples in North East plot? (Name, colour, taste, ripens).
This puzzle is included in the book The Sunday Times Book of Brain-Teasers: Book 2 (1981).
I think the puzzle as published in The Sunday Times and in the book is open to interpretation, and my first attempt using a reasonable interpretation gave two solutions (neither of which are the published solution). After examining the given solution in the book I think the following wording is clearer:
A farmer grows apples in an orchard divided into plots — three to the East and three to the West of a central track. Adjacent plots are separated by a shared fence. The apples are of two basic types — for eating (Cox, Laxton, Pearmain) and for cider making (Tremlitt, Coppin, Kingston).
Neighbouring plots contain apples of different basic type. The apples are of six colours (red, green, russet, golden, orange, yellow) and of six tastes (sweet, sour, acid, tart, pleasant, bitter).
They ripen at different times, either early or late in July, August and September. Those ripening in early or late September are in plots directly opposite each other. Those directly South of Pearmain do not ripen in August. Tart are directly West of the acid variety, which ripens in early August. Yellow apples and those maturing in late September are in adjacent plots. Yellow and orange are of the same basic type. Orange are directly North of Permain, which are pleasant. Kingstons and golden are in adjacent plots. Green is directly South of bitter.
Cox ripen in early July, and Laxtons ripen early in a different month. Tremlitts are red, and Kingstons mature after Coppins, which are not sour.
If cider apples are neither pleasant nor sweet, what are the characteristics of the apples in North-East plot?
[teaser734]


Jim Randell 2:13 am on 27 October 2024 Permalink |
There are two relevant cases to consider:
(1) The attacker used a green cane, which was correctly identified as green.
(2) The attacker used a blue cane, which was misidentified as green.
And we need the probability of case (2) to be 2/3 (i.e. it is twice the probability of case (1)).
The solution is easily found manually, but this Python program considers possible increasing numbers of blue cane carriers, until the required probability is found.
from enigma import (Rational, irange, inf, compare, printf) Q = Rational() # B = number of carriers of the blue cane for B in irange(1, inf): # probability attacker used a green cane, identified as green pGG = Q(1, B + 1) * Q(4, 5) # probability attacker used a blue cane, identified as green pBG = Q(B, B + 1) * Q(1, 5) # probability that a blue cane was used in the attack p = Q(pBG, pGG + pBG) r = compare(p, Q(2, 3)) if r == 0: printf("B={B}") if r > 0: breakSolution: There are 8 holders of the Blue Cane.
Manually:
If there are B blue canes, then (assuming each cane holder is equally likely to be the attacker):
And we want pBG to be twice pGG.
LikeLike