Teaser 3225: My extended family
From The Sunday Times, 14th July 2024 [link] [link]
When Daniela, the youngest of my nieces, was born not so long ago, her brother John remarked that Daniela’s year of birth was very special: no number added to the sum of that number’s digits was equal to her year of birth. The same was true for John’s year of birth.
“Well,” intervened Lorena, the eldest of my nieces, “if you want to know, my own year of birth — earlier than yours — also shares that very same property, and so does the year of birth of our father Diego. The same is even true for our grandmother Anna, who, as you know, was born in the 1950s”.
When were Daniela, John, Lorena, Diego and Anna born?
[teaser3225]




Jim Randell 4:43 pm on 12 July 2024 Permalink |
It is straightforward to find candidate years, and we can then fit them to the family circumstances.
I imposed a reasonable gap between generations, and although I’m not sure this is strictly necessary it does give a unique solution to the puzzle.
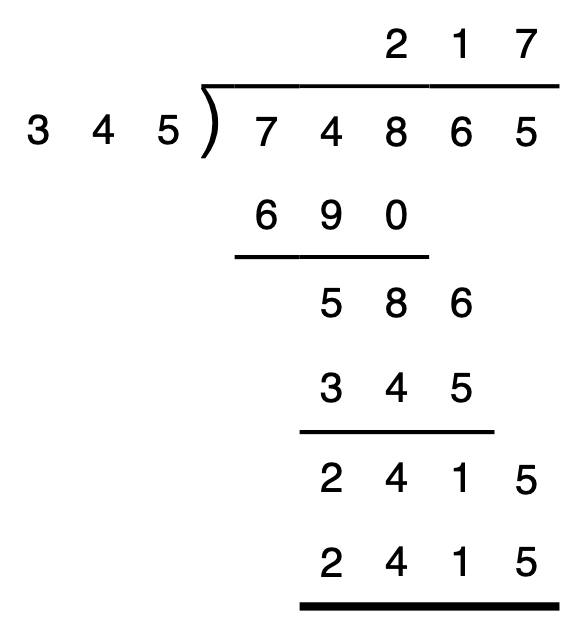
The following Python program runs in 73ms. (Internal runtime is 245µs).
from enigma import (irange, dsum, diff, subsets, printf) # find numbers added to their digit sum xs = set(n + dsum(n) for n in irange(1922, 2024)) # look for recent years not in xs years = diff(irange(1950, 2024), xs) printf("years = {years}") # enforce generation gaps gap = lambda x, y: 15 < abs(y - x) < 50 # assign birth years in order for (A, D, L, J, D2) in subsets(years, size=5): if not (A // 10 == 195): continue if not (gap(A, D) and gap(D, L) and gap(D, J) and gap(D, D2)): continue # output solution printf("A={A} D={D} L={L} J={J} D2={D2}")Solution: The years of birth were: Daniela = 2022; John = 2007; Lorena = 1996; Diego = 1974; Anna = 1952.
There are only 7 recent candidate years (shown below), and only one reasonable assignment of birth years (also shown below):
Anna was born in the 1950’s (i.e. 1952), and was (presumably) more than 11 when Diego was born, so he could be born in 1974 (when Anna was 22).
And Diego was (presumably) more than 11 when Lorena was born, so the nephews/nieces were born in 1996, 2007, 2022 (when Diego was 22, 33, 48).
And this is the only situation where there is more than 11 years between generations.
LikeLike
Tony Smith 12:01 pm on 13 July 2024 Permalink |
Biologically generation gap could be eg 11, and Diego could have been born before Anna.
These possibilities give multiple answers.
LikeLike
Ruud 7:47 am on 13 July 2024 Permalink |
We can simply with
from istr import istr print(sorted(set(range(1950, 2024)) - {int(sum(n) + n) for n in istr(range(2025))}))find that the only possible years of birth are
1952, 1963, 1974, 1985, 1996, 2007, 2022
But, given the fact that there are three generations, this leads to
Anna 1952
Diego 1974
Loreena 1996
John 2007
Daniella 2022
LikeLike
Brian Gladman 9:13 am on 13 July 2024 Permalink |
Hi Ruud,
These teasers are published on Sundays each week as a competition for prizes in the print edition of the Sunday Times. They are designed with the intention that they are solved without computer assistance. I would hence ask you not to encourage cheating by revealing solutions before the competition ends two weeks after its publication.
LikeLike
Ruud 9:31 am on 13 July 2024 Permalink |
Ok.
LikeLike